Semantic Versioning
Overview and Motivation
The shift from code-centric to model-centric software development places models as first class entities in “Model-driven Software Development” (MDSD) processes. A major prerequisite for the wide acceptance of MDSD are proper methods and tools as available for traditional software development, such as build tools, test frameworks or “Version Control Systems” (VCS). Considering the latter, VCS are particularly essential when the development process proceeds in parallel such that different developers concurrently modify a model, which may result in concurrent, potentially conflicting modifications.
Such conflicting modifications need to be resolved by appropriate techniques for model comparison, conflict detection, conflict resolution and merging, which in case of a heterogeneous tooling environment are required to operate on the resulting model (i.e. state-based).
Since, as already stated, models are the first class entities in model driven development, this should not rely on text- or tree-based VCS like Subversion, CVS. The granularity of comparison is a single line without taking into account the logical structure of models.
For dealing with concurrent modifications on models and for properly identifying conflicts, it is necessary not only to consider the syntactical structure of models but also to “understand” the model’s semantics. For example, concurrent modifications on a model may not result in an obvious conflict when syntactically different parts of the model were edited. Nevertheless, they may interfere with each other, thus yielding an actual conflict, which without considering the model’s semantics would remain hidden. Furthermore, certain conflicts may only occur due to the syntactical representation of a model, since sometimes more than one possibility exists to conceptually express the same state of affairs. Especially modeling languages offering “syntactic sugar” in the sense that convenience constructs allow to express the same meaning in varying ways, can easily give rise to the above mentioned scenario.
Whereas model comparison and model merging can be facilitated by means of existing graph-based approaches, facilitating an “understanding” of the models during conflict detection and conflict resolution is still an open issue for models. We argue that through the definition of semantics, a VCS can find conflicts more precisely during conflict detection, thus avoiding falsely indicated conflicts and finding previously undiscovered ones.
However, a full formal specification of the semantics underlying a modeling language is very often not feasible, as these are often hard and costly to define. Furthermore, In the light of a growing number of domain specific languages a flexible and more light-weight approach is desirable.
Semantic Versioning
A model conforms to a certain metamodel that defines the abstract syntax of a modeling language, which itself does not provide any machine-interpretable semantics. Most definitions of semantics are functions that map the abstract syntax of one language onto the abstract syntax of another well understood language.
In our proposed approach, the semantic mapping between a modeling language’s metamodel and a metamodel representing a certain view of interest, is defined through a model transformation. The output of such a transformation is another model which conforms to the metamodel representing the semantic view definition of interest.
As a consequence of the transformation realizing a semantic mapping, conflict detection can be carried out on both models and semantic views. We refer to conflicts that are determined purely upon the comparison of two versions of a model as syntactical conflicts whereas a semantic conflict is a conflict that is detected between the representations of such a model’s versions in a semantic view. The actual finding of conflicts in both the original model and the view functions analogous to the graph-based detection of structural conflicts in existing versioning systems.
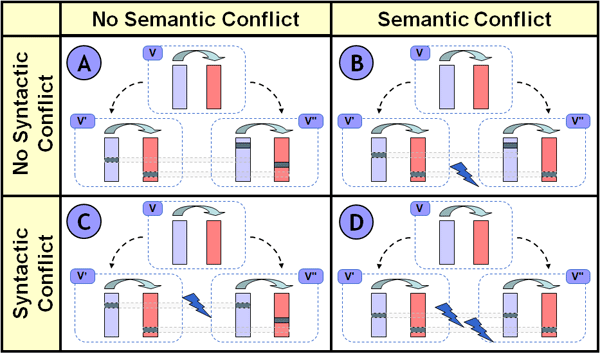
The figure above shows four possible combinations of scenarios that can occur when a model’s semantic views are incorporated into conflict detection. These scenarios are arranged according to an observed syntactic or semantic conflict, respectively. As a simplification, the figure does not make use of a concrete model, but uses bars as abstractions for models with highlights indicating a modification in a certain part of the model. The left light shaded bars refer to the original model (before transformation) and the right dark shaded bars refer to the semantic view of a model (after transformation). Thus, if changes in the model or the view occur in the same place, a syntactic or semantic conflict is detected, respectively. Of course, only the model is checked out and edited by developers, whereas the semantic view is only a product of the transformation. The common ancestor version V is shown on top of the modified versions V‘ and V‘.
Prototype
After the conceptual overview, the following paragraphs, will describe our prototype application from a more technical perspective. Furthermore, an example describes how the prototype implementation‘s check-in/check-out functionality deals with accumulating the differences between several revisions before an actual comparison takes place. In order to define the abstract syntax of a modeling language and a desired semantic view definition, a metamodeling architecture is needed. The “Eclipse Modeling Framework” (EMF) provides Ecore, which is a simplified version of MOF that constitutes an M3 layer. Furthermore, EMF covers persistence support with an XMI serialization mechanism and a reflective API for manipulating EMF models. The creation of a semantic view from a model is realized through the “Atlas Transformation Language” (ATL). The comparison of the versions (V‘syn, V‘‘syn, V‘sem, V‘‘sem) with their common ancestor (Vsyn, Vsem) is carried out on a generic graph representation of the respective models and views. For this purpose, the EMF reference implementation of “Service Data Objects” (SDO) is used. SDO allows to create “datagraphs” from EMF models, which are convenient for comparison purposes as SDO’s mechanism to establish the difference between two graphs can be used. These so called “change summaries” are used in our prototype to store modifications between versions, which are then used by the actual conflict detection mechanism. The figure blow illustrates the workflow in our proposed VCS and also includes the currently not addressed phases of conflict resolution and merge which are part of the check-in process.
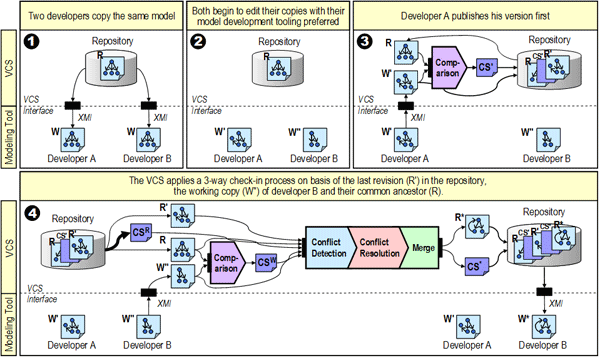
To start with, two developers A and B contact the repository and create a personal working copy (W). Developers then work in parallel, modifying their private copies (W‘ and W‘‘). Developer A saves his changes to the repository first. Because the last revision in the repository is the direct ancestor of the incoming working copy (W‘) the check-in can proceed. The file saved in the repository is the modified working copy of developer A (W‘) and the computed change summary (CS‘), provided by SDO, of W‘ and his ancestor (R). When developer B attempts to save his changes later, the repository informs him that his artifact (W‘‘) is out-of-date. Therefore, the VCS has to apply a 3-way check-in process containing the phases comparison, conflict detection, conflict resolution and merge. The process starts with comparing the working copy of developer B (W‘‘) with his ancestor (R) to determine the modifications (CSW). To be able to compute conflict detection the change summary between the last revision in the repository (R‘) and the common ancestor (R) has to be retrieved. In this workflow scenario there only exists one change summary between the revisions but if more then one exist, they have to be accumulated resulting in CSR. Now the conflict detection, resolution and merge process can start involving the developer B. Once the developer B has integrated both sets of changes, he saves the merged artifact (R) and the change summary (CS) back to the repository.
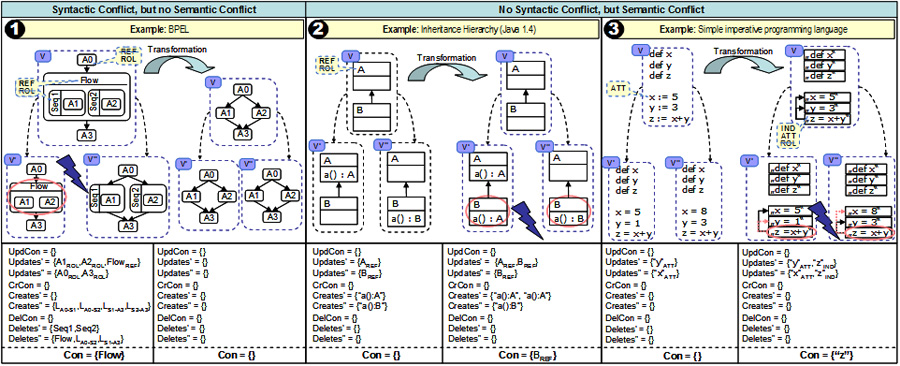
Case Study
The following paragraphs discuss an evaluation of our approach regarding its capabilities for semantic conflict detection upon three different application scenarios. To demonstrate variability two scenarios deal with behavioral and structural modeling, whereas the third scenario deals with applying our approach to imperative programming languages. As shown on the left-hand side of the figure below, the first scenario deals with conflict detection between BPEL documents. Thereby, the transformation „normalizes“ a process specification‘s Sequence and Flow constructs into a semantically equivalent structure of individually linked up Actvities. Since basically an almost arbitrary mixture of the Sequence, Flow and explicit Link constructs can be used to model a process definition, semantic conflict detection gives considerable benefits in actually separating merely syntactic from “real” semantic conflicts. Our experiments have shown us, that without semantic conflict detection, spotting the latter becomes a tedious task as they can easily be obscured by BPEL’s “syntactic sugar”. The second scenario deals with the inheritance of methods in a Java class hierarchy. Thereby we aim at detecting conflicts that involve updates of inherited methods. The concept of inheritance is made explicit through a semantic view that propagates all inherited methods down the class hierarchy, which in turn allows semantic conflict detection based on the created view. Consequently, a semantic conflict can be detected, as both developers have introduced a method with the same name but different return type. The third scenario ¸ deals with semantic versioning of a simple imperative programming language. Thereby, a program is transformed into a dependency graph, which makes explicit data dependencies between statements in the code. Thus, for instance, concurrent changes to two different statements that influence some other model element can be detected. In the example shown, this is the case as the statements setting the variables x and y are modified, which indirectly updates the statement setting the value of z. The effort for specifying the transformations for each of these examples was considerably small, as each of the above scenarios account for only about 50 to 200 lines of ATL transformation language code. Furthermore, the above examples emphasize the versatility of a model transformation-based approach, as one gains the ability to perform diverse tasks like eliminating syntactic sugar, explicate hidden concepts in models through the application of inference rules, and in general the establishment of specialized views on models.