About CrowdSA - Approach
System Architecture of crowdSA
The proposed architecture of crowdSA, which is depicted in the figure below, consists of three functional core components for realizing our three key research goals.
Figure: Overall System Architecture
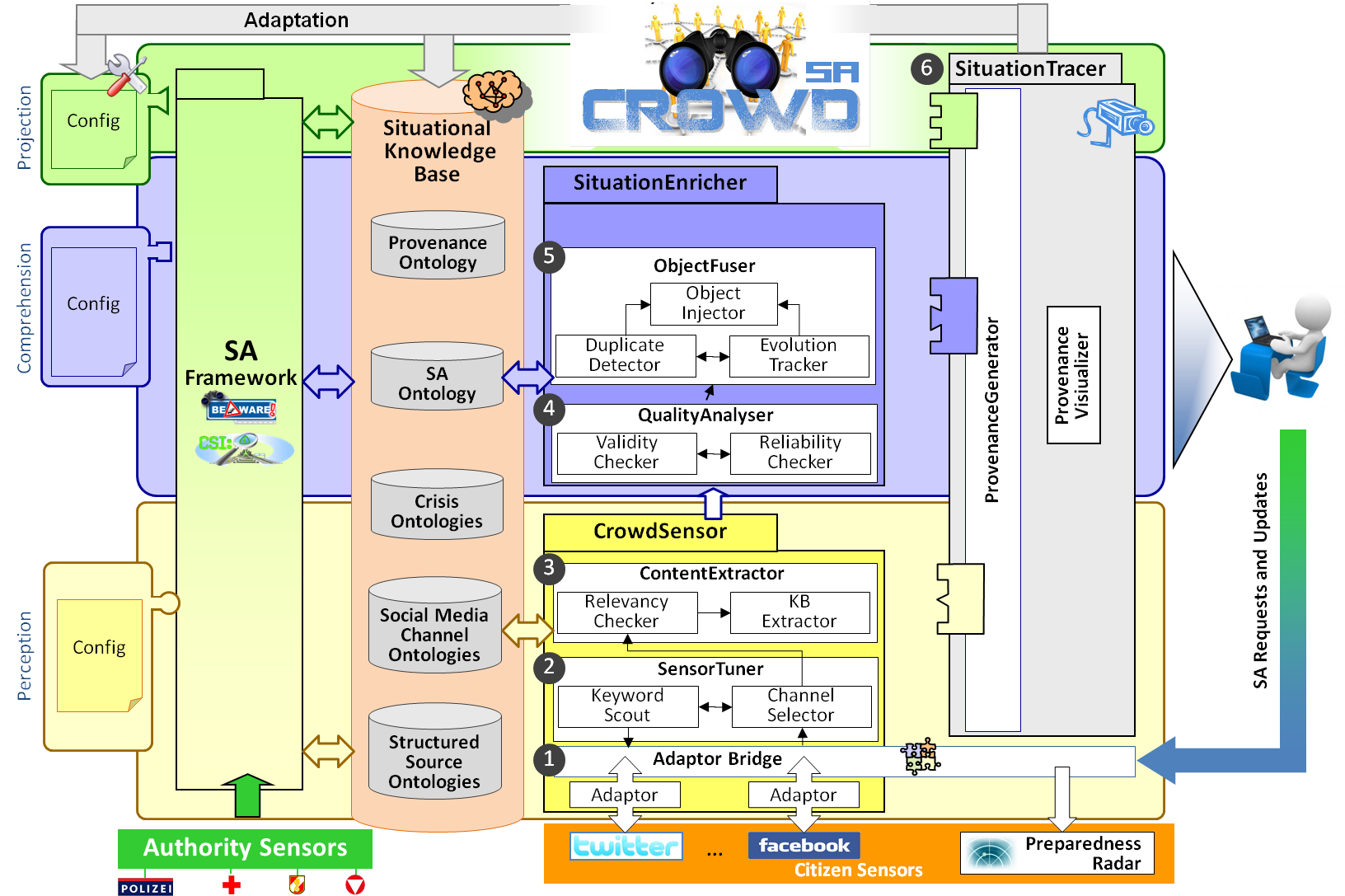
First, the CrowdSensor component is responsible for intelligently sensing relevant crisis information from various social media channels and building up structured, so-called crisis objects. Second, the SituationEnricher enhances a situational picture with quality-checked and fused crisis objects, which can be also fed back to the channels to increase preparedness of the crowd. Finally, the SituationTracer is a crosscutting component through all three levels of situation awareness, which tracks each part of an assessed or projected critical situation back to its origin. All three functional components interact with the existing BeAware!/CSI prototype via the situational knowledge base (cf. below). The subcomponents of these core functional components are described in more detail in the following subsections. Besides these functional components, there are two further central building blocks. First, the situational knowledge base, which represents the pivotal interface between the existing BeAware!/CSI prototype and crowdSA, contains not only the already developed situation awareness – SAOntology – and the StructuredSourceOntologies, but also the newly to be developed SocialMediaChannelOntologies, the CrisisOntologies, and the ProvenanceOntology. Second, following the philosophy of BeAware!/CSI, the functional components of crowdSA are generic in nature, thus requiring a configuration building block allowing adaptation of the system at each situation awareness level to the requirements at hand (e.g., incorporation of new social media channels or definition of new relevant critical situations). In this respect, for continuously optimizing and improving the situation awareness capabilities of crowdSA, an adaptation feedback loop is foreseen, thereby explicitly using the information tracked by the SituationTracer facility.
Situation Awareness Framework BeAware!/CSI in a Nutshell
In the following, a brief primer of our existing prototypical situation awareness framework BeAware!/CSI is given, representing a linchpin for the developments envisioned in crowdSA (cf. [Baum10a] for further information).
The core component of this prototype is the SA ontology used at all three levels of situation awareness, both, at design time and runtime. At perception level, adapters asynchronously connect structured information sources to import, e.g., weather conditions or water-levels into dedicated StructuredSourceOntologies which are furtheron mapped to our SAOntology. At comprehension level, critical situation types are pre-defined by domain experts, again by using the SA ontology together with a simple rule-based mechanism. These situation types are in fact built from real-world object types (e.g., bulky material) and relation types in-between (e.g., “near” bridge), based on well-known calculi from the field of qualitative spatio-temporal reasoning, covering, e.g., mereotopology, orientation, distance, or size. At runtime, a generic functional component searches for interrelated objects that match given situation and relation type definitions (e.g., a snapped tree causing a power breakdown) and projects future situation, among others, based on so-called conceptual neighbourhood graphs (CNGs), describing constraints on the transitions between relations [Baum10a] . The prototype is implemented on the basis of a pipes and filter architecture to increase scalability; filters representing different reasoning components (e.g., situation assessor) connected by pipes (e.g., Java RMI). It is largely based on Java and the Jena Semantic Web Framework1, using the Pellet OWL Reasoner2 as well as the RDF triple store AllegroGraph3.
CrowdSensor Component
AdapterBridge: To facilitate extensibility wrt. incorporating further social media channels, the AdapterBridge (cf. Fig. 2) should enable the plugin of adapters, which serve two purposes. First, each adapter allows to invoke dedicated APIs and/or search engines providing access to a certain social media channel in order to retrieve appropriate crisis information, covering both, unstructured content and structured metadata, if available. Second, each adapter transforms the retrieved result (JSON) into a homogenous format (based on OWL) and stores them within dedicated SocialMediaChannelOntologies (e.g., Twitter message ontology) in our common situational knowledge base. Second, each adapter additionally uses dedicated APIs to issue requests for information and updates of the situational picture into a certain social media channel. As implementation platform for the AdapterBridge, existing triplifiers (e.g., [Nuzz10] ) will be used as a starting point to rapidly integrate social networks into the ontology repositories. Later, a model-driven approach is envisioned, complementing these triplifiers to facilitate coping with social media evolution, as experienced in TheHiddenU project [Kaps12] . For this, the meta-modelling framework Eclipse EMF1, including the tools Xtext and Xtend for text (de-)serialization and transformation, could be chosen due to their maturity and large community support.
SensorTuner: The retrieval process of adapters is governed by the SensorTuner component, delivering channel-adequate tuning parameters such as keywords expressing the information need, scoring options, or pull-/push adjustments. It comprises a ChannelSelector, a KeywordScouter, and a RelevancyChecker. ChannelSelector. The ChannelSelector suggests appropriate channels to be sensed, dependent on the information need, accessibility, or performance and decides on the access frequency. For example, during pre-crisis phase, all channels will be infrequently accessed following the principle of indiscriminate all-round distribution, while during the in-crisis phase, access frequency will be increased and the main attention will be turned to determined channels, potentially fed by an intentionally contributing crowd. KeywordScouter. The KeywordScouter proposes an initial seed of keywords, representing the information need, driven by the lack of knowledge within the already existing situational picture. It is based on our SAOntology and the CrisisOntologies and will be enriched considering the nature of crowdsourced information, e.g., by abbreviations, as well as contextually relevant terms for ambiguous keywords (e.g., “flood of water” vs. “flood of people”) by using query expansion mechanisms [Mass11] and existing tools like “Google Insights for Search”. These keywords are used as direct input for sensing relevant information or as a basis for assembling concrete questions, furtheron posted to the crowd. RelevancyChecker. The subsequent RelevancyChecker employs ML-based mechanisms, e.g., support vector machines (SVM’s), to determine the relevancy of sensed information, by detecting and filtering-out potentially irrelevant one. The result will be a ranked list of potentially relevant unstructured content, e.g., tweets, together with metadata, comprising temporal, spatial, thematic, profile, and attention information (e.g., views or listens).
ContentExtractor: The ContentExtractor should extract (i) thematic aspects, comprising crisis-related entities, extent of an entity, (e.g., a heavy flood), relations between entities (e.g., the Colonel bridge representing the bridge in Colonel), and impacts (e.g., mud covered building) (ii) time aspects, e.g.. “10 minutes ago”, and (iii) location aspects, e.g., “near the crossing of”. For this, a hybrid information extraction approach will be employed, using knowledge-based techniques and a selection of different machine learning methods, based on our experience gained in the HybridIE project [Feil12] . In particular, NLP techniques will be combined with rules to incorporate domain-knowledge (e.g., crisis describing terms, relations, phrases, etc.) and knowledge on the peculiarities of the language used in posts, (misspellings, grammar, etc.). As implementation platform, we will employ the GNU-licensed open source framework GATE (Generalized Architecture for Text Engineering) [Cunn02] , providing a pipeline architecture which allows for the definition of cascading components, including a tokeniser, an ontology-PlugIn, and transducers, enabling finite state transduction over annotations based on regular expressions. PlugIn-components have to be evaluated according to peculiarities of the language used in posts, e.g., dedicated POS-Taggers have to be employed [Gimp11] . For establishing the knowledge base we will base on existing crisis-related ontologies as described above and extend them for our purposes. ML techniques, e.g., SVM’s or Conditional Random Fields (CRF) will be used on the one hand, for tasks requiring to classify previously unidentified factual relationships, e.g., burst detection (a sudden surge of the frequency of a single term or phrase in a text stream, [Zhao10] ), on the other hand, to further improve the results of the knowledge-based extraction.
PreparednessRadar: In order to enhance preparedness of citizens, defining appropriate requests and updates of the situational picture will take into account research wrt. “dialogical emergency management” [Artm10] . As delivery channels, we will not only simply use social media channels (e.g., Facebook wall of a citizen), but also provide a convenient visual spatio-temporal situation overview via a so-called PreparednessRadar. For implementation, we envision a smartphone application including a radial visualization as successfully demonstrated by Livnat et al. [Livn05] and in our previous work on visualization of collaborative traffic situations [Baum12] .
SituationEnricher Component
QualityAnalyser: Not least since concepts for quality analysis of crowdsources in crisis management is rare (as already discussed), we try to approach this challenge from two different angles: A ValidityChecker assesses the accuracy, i.e., the potential truth of information, while a ReliabilityChecker assesses the precision, i.e., the consistency of information over time.
ValidityChecker - First, the quality of crisis objects can be validated on basis of a range of facts partly held by the crowdSA situational knowledge base or being part of external sources, covering (i) knowledge about the environment (e.g., geo-position or other properties of certain infrastructural elements), (ii) epistemic knowledge (e.g., preconditions of states, events and actions, their possible direct/indirect causes and effects), and (iii) situational pre-knowledge (e.g., assessed situations or historical information about evolution patterns of a certain flood). Based on such knowledge, analysis may be performed with respect to the mere existence of certain facts (road incident reported refers to an actually existing road), but also concerning their feasibility with respect to propositional properties of a crisis object (e.g., whether the extent of a reported forest fire spans actually the area of a forest) or relational properties providing evidence whether the object is in valid relationship with others (e.g., a reported bridge collapsing on a motorway really leads over the motorway, not over a river). In order to handle the qualitative nature of crisis information, we envision to employ so-called constraint networks [Yang97] , also used in the area of spatio-temporal reasoning, e.g., for governing robot movements (i.e., preconditions of actions, actions, and effects). Thereby, crisis objects being inconsistent with the spatio-temporal theory defined in such a network (e.g., a real-world object can only be fully contained in another one if it is smaller) can be filtered, subsets of consistent objects built, and missing or uncertain relationships between crisis objects identified.
ReliabilityChecker - We envision assessing the reliability of crisis objects on the basis of statistical reliability tests on pre-existing or computed metadata about crowdsources. Such metadata comprise, e.g., the number of observations of a certain incident and the number of re-tweets (i.e., evidence of corroborating information), the number of extenuating or disproving information items, identifying whether the crisis object stems from an opinion leader or a follower, and considering the fact that timely information may be of more value with respect to its topicality but later information may base on more observations.
ObjectFuser: Object fusion comprises the tasks of duplicate detection (DuplicateDetector), also in presence of evolution of crisis objects (EvolutionTracker), and finally data fusion among crowdsourced information and injection into existing SA information (ObjectInjector).
DuplicateDetector - For realizing a dedicated DuplicateDetector component, we base upon the strategy to base similarity judgement on (multiple) relation similarities if present, expressed by spatio-temporal calculi and CNGs [Baum10a] . The DuplicateDetector will comprise rule-based similarity measures defined by domain experts, which are accompanied by distance-based ones. With rule-based similarity measures, domain experts can express their knowledge for detection of identical information (e.g., two objects are duplicates, if they are in a same-type- and equal-region relationship). Complementary, with distance-based similarity measures duplicates in incomplete and contradictory information can be detected as well (e.g., two snapped trees reported breaking down a power line being in VeryFar relationship from distance calculus are less likely duplicates then such being VeryClose).
EvolutionTracker - Such distance-based similarity measures, which in fact resemble dynamic reasoning on the basis of CNGs developed in the field of qualitative spatio-temporal reasoning, are also suitable to cope with object evolution in a rapidly evolving crisis (i.e., two relevant information items may represent the same real-world object at different times), and thus, exploited by the EvolutionTracker.
ObjectInjector - For realizing the ObjectInjector, fusion strategies are envisioned as proposed by [Blei08] , to fuse duplicates stemming from unstructured sources into a single coherent representation, and to integrate crowdsourced information with existing structured situational information. These strategies are envisioned in a twofold manner: First, fusion strategies for isolated objects and their metadata will mainly focus on the properties of objects. Second, strategies for situations will focus on the relations between objects. Both will target the spatio-temporal nature of objects and situations, and influence factual knowledge as well as metadata (confidence of reliability, etc.).
SituationTracer Component
ProvenanceGenerator: To ensure that the other functional components of crowdSA remain oblivious wrt. the collection of provenance information, we intend to employ either aspect-oriented techniques [Kapp11] or higher-order transformations (HOTs) using the prominent ATLAS Transformation Language [Tisi09] . This would allow to weave provenance generators into existing components at each level of granularity.
ProvenanceRepository: To achieve a proper representation of provenance information in the ProvenanceRepository, the existing OPM [More08] should be extended to cover not only course-grained but also fine-grained provenance information, especially also considering who has produced a certain value.
ProvenanceVisualizer: The crucial pre-requisite for a proper self-explanatory visualization is, to enable browsing of the data dependency graphs resulting from the ProvenanceGenerators at different abstraction levels. Thus, the ProvenanceVisualizer should allow, besides obligatory search facilities, to navigate the complete trace from, e.g., a certain social media source to a specific situation enhancement, step by step, forwards and backwards. Since a proper visualization heavily depends on the preferences of the targeted users, we will work in close collaboration with our demonstration partner. For implementation purposes, we will utilize existing graph visualization libraries (e.g., SigmaJS1 or the JavaScript InfoVis Toolkit2 for provenance visualization on the Web, or Gephi3 for rich-client visualization).